ABIS Infor - 2019-06
De nieuwe Hadoop software stack
Samenvatting
Hadoop is een open source-project dat een framework levert voor het opslaan en verwerken van volumineuze data op een schaalbare en gedistribueerde manier. Bovenop dit "basis"-raamwerk werden gradueel een aantal bijkomende open source-producten ontwikkeld die zeer populair zijn onder Data Scientists. Deze collectie tools wordt dikwijls de "Hadoop Stack" genoemd.
Sinds z'n initiële release in 2006 is Hadoop uiteraard verder gegroeid en geëvolueerd. Maar vooral de bouwblokken in de Hadoop Stack zijn ondertussen drastisch gewijzigd: sommige software-producten die enkele jaren geleden populair waren, zijn in onbruik geraakt, terwijl andere in beeld gekomen zijn; sommige werden zelfs zo belangrijk dat ze vandaag de echte Hadoop! "front end" zijn!
Hadoop "basis"
De origines van Hadoop gaan terug tot de jaren 2003–2006, toen Doug Cutting en Mike Cafarella het Google gedistribueerde filesysteem GFS en Google's MapReduce idee herimplementeerden in Java. Dit gebeurde binnen een web crawler project genaamd Nutch. Sindsdien is Hadoop blijven groeien in functionaliteit en in aantal gebruikers; en ook het aantal personen die aan de broncode bijdragen is gegroeid. Hadoop is momenteel een project van de Apache Software Foundation: een non-profit-organisatie die momenteel meer dan 350 open source softwareprojecten huisvest.
Het hoofddoel van Hadoop kan als volgt samengevat worden: het biedt een stabiele laag, vergelijkbaar met een besturingssysteem, voor het opslaan van data (zoals een bestandssysteem) en het uitvoeren van gegevensmanipulaties (zoals een taakbeheerder), bovenop een TCP/IP-netwerk van onafhankelijke en mogelijk onbetrouwbare computers (die de nodes genoemd worden) van een zogenaamde computer cluster.
Deze gedistribueerde layout voor opslag & computing laat in principe een onbegrensde "opschaling" toe, zowel in opslagcapaciteit als in parallelle rekencapaciteit. Dit is o.a. mogelijk doordat hardware-fouten (b.v. gecrashte schijven) opgelost worden door de betreffende node gewoonweg te vervangen.
Hadoop bestaat uit drie basisbouwblokken:
- HDFS, het Hadoop Distributed FileSysteem. Deze abstractielaag geeft de gebruiker een unix-stijl hiërarchisch filesysteem; daarbij verbergt men de details van (1) het in stukken knippen van grote bestanden in kleinere partities die over verschillende nodes verspreid worden en van (2) het dupliceren van elke partitie over meerdere nodes (standaard 3) om fouttolerant te zijn.
- MapReduce, het computationele framework, laat programmeurs toe hun eigen dataverwerkingsalgoritmes te schrijven op een parallelliseerbare manier, zodat het behandelen van verschillende partities van de input-data in parallel kan gebeuren (d.w.z.: terzelfdertijd op verschillende nodes) wanneer dat voor het algoritme zinvol en mogelijk is: dit is de "Map"-fase. Het framework doet dan de nodige "shuffling" van data tussen nodes vooraleer de finale "Reduce"-fase uitgevoerd wordt (die typisch niet in parallel loopt, maar typisch op een veel kleiner datavolume zal werken).
- Yarn, "yet another resource negotiator", is de taakbeheerder die jobs (d.w.z.: fases van MapReduce-programma's) toekent aan deelnemende nodes die beschikbare (reken)capaciteit hebben, en die bij voorkeur één van de drie kopieën bevatten van de relevante partitie van de input-data.
De Hadoop Stack
Zoals je kan ontdekken door te zoeken naar de term "Hadoop stack", en meer in het bijzonder naar grafieken of plaatjes voor die zoekterm, en wanneer je dan oudere en nieuwere plaatjes met elkaar vergelijkt, zal je zien dat de stack van software-producten (en meer specifiek: Apache-producten) die op Hadoop bouwen, constant wijzigt. Elke software-leverancier zal uiteraard z'n eigen versie hebben van die stack-grafiek, waarbij ze de belangrijke plaats in de verf zetten van hun eigen software-product in die context!
,
Laten we proberen, vendor-neutraal te zijn en ons te concentreren op Apache-producten die populair zijn en die algemeen als bruikbaar worden bestempeld. Hieronder is de nieuwe Hadoop Stack, met wat wij bij ABIS momenteel (2019) beschouwen als de interessantste Apache-producten die gebruik kamen van de genoemde drie Hadoop basisbouwblokken, rechtstreeks of onrechtstreeks.
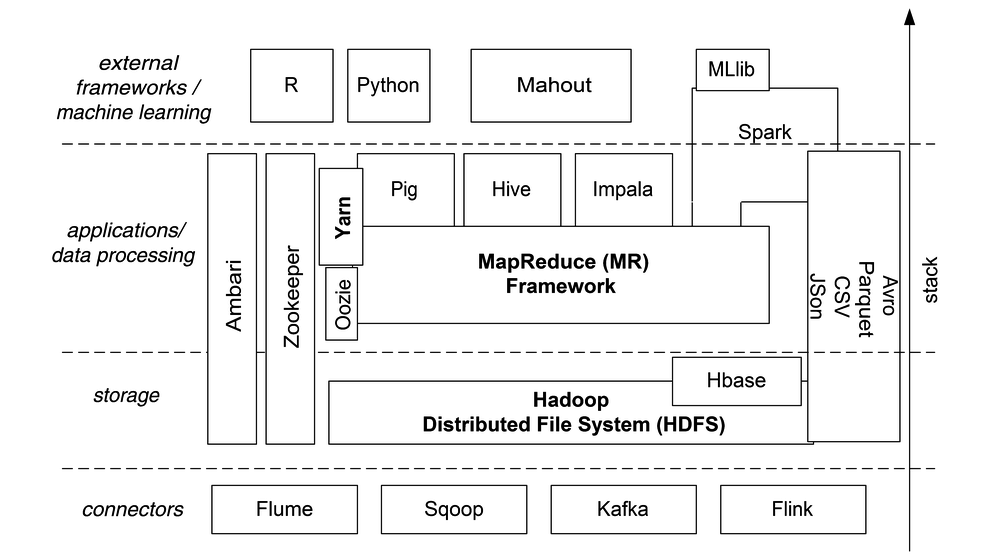
De bouwblokken in een notendop
Behalve de drie "basis"componenten van Hadoop (met name HDFS, MapReduce en Yarn), kunnen de bouwblokken ruwweg onderverdeeld worden in vier categorieën: connectors (naar externe data), opslag (en bestandsformaten), gegevensverwerking (vooral front-ends voor MapReduce), en toepassingen van een hoger abstractieniveau (b.v. machine learning) en interfaces naar programmeertalen.
- Flume is bedoeld voor het "streamen" van grote volumes log data, en het efficiënt opslaan daarvan op HDFS.
- Sqoop laat bulk data transfer toe tussen HDFS en relationele databases. Wordt echter meer en meer overbodig.
- Kafka is een zeer populaire message broker, b.v. voor het streamen naar HDFS van data die website-activiteit trackt.
- Ook Flink is een stream processing framework; belangrijkste use case: event-driven analytische applicaties uitvoeren.
- In dezelfde "connector"-categorie kunnen we ook Avro en Parquet noemen: dit zijn bestandsformaten. Avro is eigenlijk een dataserialisatiesysteem dat toelaat om een grote verscheidenheid aan data (en metadata) te aggregeren in een binaire file, en het kan over een RPC client-server-link gebruikt worden. Ook Parquet is een binair bestandsformaat, maar specifiek gericht op gestructureerde (tabulaire) data zoals typisch gebruikt door MapReduce-jobs. CSV and JSON zijn ook populaire bestandsformaten die hier enkel vermeld worden om volledig te zijn: dit zijn uiteraard geen Apache-producten, en ze worden in een veel bredere context gebruikt dan Hadoop.
- Hbase is een NoSQL database management system (DBMS), één van de vele; maar het is het enige binnen het Hadoop-ecosysteem; meer specifiek heeft het HDFS nodig. Het is eigenlijk een kloon van het door Google gepatenteerde Bigtable.
- Ambari is een administratie-tool voor een Hadoop-cluster: Ambari heeft een web-gebaseerd dashboard voor monitoren & alarmen, een eenvoudig te gebruiken webinterface voor het starten en stoppen van nodes & services, en voor het installeren/upgraden van software op alle nodes.
- Zookeeper helpt administrators op een andere manier: het is een centrale opslagplaats voor configuratie-settings van alle nodes in de cluster. Deze data is trouwens zelf gedistribueerd, dus "gecentraliseerd" betekent geenszins "single point of failure"!
- Oozie zit conceptueel dicht bij Yarn, maar in een andere fase van het proces van job-scheduling: het laat een administrator toe om lopende jobs te beheren: het laat ook een eindgebruiker toe om gegevensstromen binnen een job te visualiseren, evenals de afhankelijkheden tussen verschillende job-stappen.
- Hive is de eigen SQL front-end van Hadoop: het werkt precies als een optimizer in een relationele database: het vertaalt SQL-queries naar MapReduce-jobs (mogelijk meer dan één job voor één query). Daardoor worden de algoritmische finesses (die laag-niveau MapReduce-logica bevatten) weggeabstraheerd van de eindgebruiker.
- Pig is zeer gelijkaardig aan Hive: het vertaalt een hoger-niveau algoritmische beschrijving naar het lagere niveau van de MapReduce-jobs. De interface-taal van Pig laat toe, namen te geven (als variabelen) aan tussenresultaten. (Een beetje zoals de RDDs van Spark.)
- Impala gaat een stap verder dan Hive: het gebruikt Hive waar mogelijk, maar is in de eerste plaats een hoger-niveau SQL query engine, een soort RDBMS dus, die gebruikers ook toelaat om HBase-data of Parquet-files te ondervragen.
- Spark is van een andere schaal dan de meeste reeds genoemde software-producten: het biedt een "all-in-one" oplossing in de vorm van een uniforme eindgebruikerservaring, voor functionaliteit die gelijkaardig is aan die van Pig en Hive, plus extensiebibliotheken voor stream processing en voor machine learning. Bovendien laat het toe, tussenresultaten (tussen MapReduce job-stappen) optioneel in het geheugen op te slaan, waardoor de MapReduce-stap(pen) drastisch kunnen versneld worden vergeleken met b.v. Hive.
- Mahout is een machine learning-omgeving bovenop Hadoop, met implementaties voor b.v. clustering en classificatie. Net zoals Pig en Hive vertaalt Mahout de vraag van de gebruiker naar Java-code voor MapReduce-jobs. Bemerk dat een Spark-gebruiker nooit Mahout zal gebruiken vermits Spark een alternatief voor Mahout heeft ingebouwd, namelijk z'n uitbreidingsbibliotheek genaamd MLlib.
- R is geen Apache-product, en ook niet in een ander opzicht nauw verwant met Hadoop. Toch is het de moeite om R te noemen, omdat het een populaire open-source front-end is voor het verwerken van grote collecties data, vooral dan onder statistici. Bovendien is het één van de weinige expliciet ondersteunde gebruikers-interfaces voor Spark. Behalve z'n statistische en grafische functionaliteit (die het een interessant alternatief maakt voor b.v. SPSS of SAS) is R populair omwille van z'n grote collectie open-source bibliotheken.
- Ook Python is uiteraard geen Apache-project, maar een populaire generieke programmeertaal. Net zoals R werd Python een zeer populaire interface voor data scientists, dankzij z'n grote collectie open-source bibliotheken. Ook Python is één van de expliciet ondersteunde gebruikersinterfaces voor Spark (naast R, Scala and Java).
Uiteraard is deze lijst verre van compleet. Nieuwe functionaliteit en zelfs nieuwe software wordt toegevoegd terwijl ik deze tekst aan het typen ben... Maar zie het als een goed startpunt, indien u de hierboven genoemde Apache-producten eens wat dichterbij bekijkt. Zeker de inspanning waard!
Conclusie
Het Hadoop-ecosysteem is een nog steeds snel evoluerende set van bouwblokken, al lijkt het nu stilaan te stabiliseren. Meer weten? Consulteer de lijst van ABIS trainingen over dit onderwerp!